LLM Tutorial
SkyrimNet – Understanding LLMs for Roleplay

1. What is an LLM?
A Large Language Model (LLM) is an AI system trained on vast amounts of text to generate natural language based on a prompt.
In SkyrimNet, the LLM acts like an improvisational actor — it reads game context, NPC memory, and triggers, then “performs” dialogue, narration, or actions that feel believable in Skyrim’s world.
Think of the LLM as the brain of your AI characters, with SkyrimNet as the nervous system that feeds it information and acts on its decisions.
2. Key LLM Settings
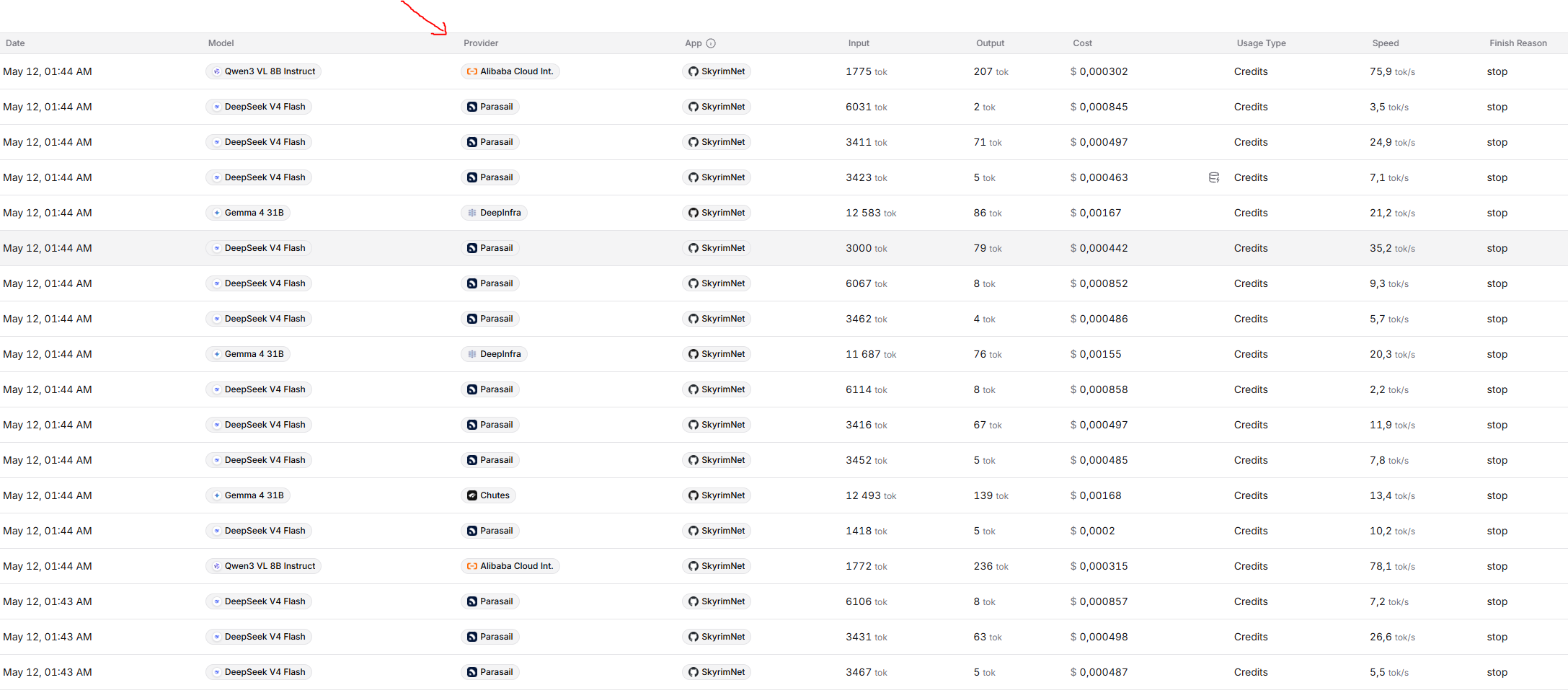
Tokens
Tokens are small chunks of text, usually a few characters long. LLMs have a maximum token limit, which is split between the input (prompt) and the output (response). Long conversations, NPC histories, and game event logs all need to fit into this limit, or older information will be dropped. However since skyrimnet is structured in relatively small api requests, token limitations will hardly ever be an issue. If needed, max token length can be increased in the settings. While tokens and words are related, they are not the same thing. On average, one token corresponds to roughly ¾ of an English word, meaning that 100 tokens might represent about 75 words of normal text. This is only an approximation—short, common words may take just one token each, while rare or compound words, numbers, and symbols can take multiple tokens. For example, “mountain” is usually a single token, but “Dovahkiin’s” might be split into several because of the apostrophe and less common root.
Context Size
The amount of conversation and history the LLM can “see” at one time. Larger context sizes let the model remember more backstory, relationship history, and past events in a scene without forgetting earlier details.Though this is just for the current context window. Skyrimnet long-term memory system and dynamic bios will ensure that characters will remember events well beyond this recent history.
Temperature
Controls how creative or predictable the AI is.
Lower values (0.1–0.3) make it precise and focused, while higher values (0.8–1.2) make it more unpredictable and creative. Mid-range values often produce natural, human-like conversation.
Repetition Penalty
Discourages the model from repeating itself. A moderate penalty keeps dialogue varied without sounding forced. Too little penalty can cause looping speech; too much can make phrasing awkward.
Top-P (Nucleus Sampling)
Instead of pure randomness, Top-P limits the possible next words to those that make the most sense in the moment. Lower values keep the model more focused, higher values allow more variation.
Frequency Penalty
Prevents the AI from overusing the same words or phrases too often, helping to avoid repetitive sentence structures and keeping the conversation fresh.
3. Roleplay Tuning Tips
- Aim for immersion: Use mid-range temperatures so NPCs feel lively without becoming nonsensical.
- Add personality variety: Adjust temperature and Top-P slightly for different NPCs to give them distinct speaking styles.
- Avoid conversation loops: Use repetition and frequency penalties together to keep dialogue progressing naturally.
4. Why This Matters in SkyrimNet
These settings directly affect:
- How consistent NPCs are with their established personalities.
- How immersive roleplay feels over extended sessions.
- How well the AI balances creativity and control when driving dialogue, narration, and in-game actions.
SkyrimNet LLM Setup — Quick Tutorial (OpenRouter + DeepSeek V3 0324)
This guide walks you through the exact LLM settingsand explains what each does, plus a few safe tweaks for roleplay, combat, and actions.
1) Provider Setup
Path: Advanced Configuration → OpenRouter
- Provider Type:
openrouter - Model Name:
deepseek/deepseek-chat-v3-0324 - API Endpoint:
https://openrouter.ai/api/v1/chat/completions - API Key: Your OpenRouter key
Max Context Length: 4096
How many tokens (prompt + reply) SkyrimNet will pack into each request.
Timeouts
- Request Timeout:
15s(total request processing window) - Connect Timeout:
2s(time to establish the connection)
Provider Settings (JSON)
{
"cache": true,
"route": "fallback"
}
Provider Settings
-
cache:
true
Lets OpenRouter reuse identical responses where possible. -
route:
"fallback"
Allows automatic routing to a backup path if the primary is down.
Generation Parameters
-
Temperature:
0.699999988
Mid-range creativity for natural, lively dialogue without chaos. -
Max Tokens:
4096
Upper bound for the model’s reply. Keep high for long scenes; reduce if you need to save tokens for context. -
Top P:
1
Full probability mass. Pairs well with the mid temperature above. -
Top K:
5
Limits choices to the 5 most likely next tokens at each step. Adds focus and reduces fluff. -
Frequency Penalty:
0
No penalty for reusing words. Good for consistent tone; consider0.2–0.4if you notice repetitive phrasing. -
Presence Penalty:
0
No push toward new topics. Keeps characters “on subject.” -
Stop Sequences:
[]
None configured. Optional: add custom stops like["<END>"]if you’re templating multi-part outputs.
Context Configuration
- Event History Count — Dialogue:
50
Number of recent events SkyrimNet includes when composing dialogue.
Higher = more continuity, but uses more of your 4096-token window.
Why These Defaults Work
- DeepSeek V3 (0324) balances cost, speed, and reasoning—solid for Default dialogue, combat banter, memory wording, and action selection.
- Temp ≈ 0.7 + TopK 5 gives expressive but grounded speech.
- No penalties keeps the character’s voice stable; SkyrimNet’s memory & prompts do the heavy lifting for variety.
Safe Tweaks by Use Case
Story-heavy roleplay
- Temperature:
0.7–0.85 - (Optional) Frequency Penalty:
0.2to reduce repeated phrases in long scenes.
Combat / mechanical decisions
- Temperature:
0.2–0.4 - TopK: keep
5(or raise to10if replies feel too terse).
Long scenes with many speakers
- Keep Event History Count at
50but watch token usage. - If you hit the 4096 window, lower Max Tokens (reply) to
1200–2000.
Looping or catchphrase repetition
- Frequency Penalty: bump from
0→0.3–0.6.
Token Budgeting Tips
The 4096 context length is shared by:
- System + template
- Memories
- Events
- Your new prompt
- The model’s reply
This size will usually be more than enough for each context window, but you can raise it, if needed. Also if you want to try and reduce token useage you can experiment lowering it. If replies are then getting cut off:
- Lower Event History Count (e.g.,
50 → 30) - Lower Max Tokens for the reply
- Tighten prompts and memory snippets (advanced, see prompt tutorial)
Reliability Checklist
- Time-outs: If you see intermittent failures, raise Request Timeout to
30–60s. - Routing: Keep
"route": "fallback"to avoid provider outages.
Quick Reference
- Provider: OpenRouter
- Model:
deepseek/deepseek-chat-v3-0324 - Context:
4096 - Timeouts:
15s / 2s - Temp:
~0.7 - TopP / TopK:
1 / 5 - Penalties:
0 / 0 - Event History (Dialogue):
50
These settings are a strong baseline. Adjust temperature and penalties per NPC or scene to shape voice and variety without sacrificing consistency.